'%20style='fill:%20rgb(104,%20183,%20176);%20fill-opacity:%201;'%20class='fills'/%3e%3c/svg%3e)
'%20style='fill:%20rgb(93,%20127,%20229);%20fill-opacity:%201;'%20class='fills'/%3e%3c/svg%3e)
'%20filter='url(%23a)'%20style='fill:%20rgb(245,%2079,%2079);%20fill-opacity:%201;'%20class='fills'/%3e%3c/svg%3e)


Welcome back once again, glad you're still with me! We are still hacking away at advanced scripts on Anki cards.
Building on the first two posts where we used scripts to create templates, we will do another thing today that scripts are really good at. We are going to create a lot of cards. We will also see how incomplete data can still be useful if the needed data can be inferred from other fields that we do have, when we generate Hiragana automatically from Kanji.
The post is designed so you can try everything on your own computer. We are going to start from the solution of the second post and improve it together for more data. Instead of doing everything yourself, you can also view the end result on University of Vienna Gitlab.
To talk about creating a lot of cards, let's first define some Anki terms: When you add something to Anki, you don't add cards directly, but instead something that is called a note and of a specific note type. The note type, say, "Japanese vocabulary", defines a number of fields, like "English", "Japanese", etc., and a number of templates, for example one template for cards to translate English into Japanese and one for the reverse. Cards can be organized into sets called a deck, e.g. "Lesson 1", which you can select Anki's main interface to start a practice session.
What happens when you use Anki's "Add" interface, select the "Japanese vocabulary" type and some deck, fill out English and Japanese and hit "Add" is that a new note will be created, and then the note will be applied to all templates of its note type to produce cards, and all non-empty cards will be added to the deck of your collection you have selected. Let's stop for a moment and appreciate that this is cool. With this interface, a dedicated user can already create a lot of cards manually in relatively little time, with no code needed. In other cases, you may already have the vocabulary in a machine-readable format like CSV and just want to add it to Anki. Anki can do that very flexibly with the built-in import dialog, so if all the data you need is in the CSV, there is no need to jump straight to code. So, the first and most obvious way to create a lot of cards is to use what Anki offers you in its user interface.
Despite these excellent built-in tools, I still ended up using code to create most of my cards. My personal reason was that adding the cards with all the necessary information was too repetitive and error-prone for me, even with CSVs that I then polished up later in Anki, and that I wanted to take advantage of resources that were already out there, like existing tools in various programming languages to generate Pinyin for Chinese characters. Neither did I want to constantly look up radicals on the internet or count strokes when this sort of information is available in many open-source databases. I wanted a computer to do the boring stuff for me, which in theory should be much more reliable than lil' old me to achieve consistent quality of the data. By the end of this post, you'll be able to do the same thing and create a lot of high-quality cards with your new skills.
Sure, no problem!
To do it with code, you use Ankis python package and write some python code. We learned in the last post to create a python virtual environment with this package installed and used the package to manage templates and generate APKGs, but did very little in terms of vocabulary, either re-using an existing APKG, or creating a single note. We are going to change that in this post and start creating a lot more.
Last time, we decided against the dangerous approach of working directly on the
collection in Anki you work with day-to-day, and instead worked with an
approach where our scripts generate APKG files that we can import back into
Anki. In this post, we will continue working on the second approach in
create_from_scratch.py where we
create a note type ourselves without a reference file, and extend it to add
more notes.
First, we need some data, preferably more than we would want to write down ourselves. Luckily, a lot of people have come before us and dedicated a lot of time and effort into collecting lists of vocabulary, and a lot of the data they collected is machine-readable. For creating Anki cards, you mostly want to work with CSV or Excel files, but if no other source is available, it can still be effective to try and parse PDFs or other more tedious formats.
Let's use a list from sph-mn/nihongo on Github called jouyou-kanji.csv.
Go to the file on Github
and download its raw contents. Put the file into the directory where you keep
your code. That's 2136 Kanji you don't have to write down yourself. In this
case, we just want a CSV to practice scripting in Anki, but if you want to publish
something based on data you don't own the rights on, please make very sure you have permission of the authors to do so,
and give them credit in a prominent place.
Let's start our work by renaming create_from_scratch.py to
create_from_scratch_with_csv.py and then deleting the part
where we create and add our one and only note to the collection we have added.
In its place, we use data from the CSV using python's built-in csv module:
deck_id = col.decks.add_normal_deck_with_name("Lots of Kanji").id with open("jouyou-kanji.csv", "r") as csv_file: # make sure to use space as the delimiter (interesting choice but very readable in the raw form) # example line: '譜 "musical score" fu' csv_lines = csv.reader(csv_file, delimiter=" ") for line in csv_lines: note = Note(col, note_type_id) # make up a unique ID by assuming the Kanjis are unique note.guid = f'kanji-{line[0]}' # first column is Kanji note["Back"] = line[0] # second is english translation note["Front"] = line[1] col.add_note(note, deck_id)
For the last part with the APKG export, let's use the same code with only the
filename changed to "./lots_of_kanji.apkg".
Let's run with:
pipenv run python create_from_scratch_with_csv.py
This time it will take a bit longer, and may print some messages about blocking
the main thread (you can ignore those). Finally, you'll see the new
lots_of_kanji.apkg. Import it into Anki and tada, lots of new card to learn!
Sometimes, no single data source you can find will contain all the data you need. The list we downloaded, for example, has Kanji, English and Rōmaji. What if we want to practice Hiragana too?
In such cases, you may be able to combine the data of multiple data sources. Excel files that complement each other, electronic dictionaries or databases that you can access from python, get creative to complete your data in code. Calculating data automatically is an area where the advantages of managing cards in code really shine through.
Let's try this ourselves by generating Hiragana automatically using the python
package
kanjiconv. To make this package
available in our script, add this line to the [packages] section of our
Pipfile:
kanjiconv = "==0.1.2"
Then install for your changes to take effect:
pipenv install
Then, we need a place to store the Hiragana in. Until now we only had
Front (English) and Back (Kanji), so let's add a third field with the
name Hiragana to the flds of our note type as the third element in the
list and with ord and id both set to 2 (the third field):
{ 'name': "Hiragana", 'ord': 2, 'id': 2, 'sticky': False, 'rtl': False, 'font': 'Arial', 'size': 20, 'description': '', 'plainText': False, 'collapsed': False, 'excludeFromSearch': False, 'tag': None, 'preventDeletion': False }
Then, all that's left for us to do is to have kanjiconv calculate the
Hiragana for us in the CSV loop:
from kanjiconv import KanjiConv kanji_conv = KanjiConv(separator="/") deck_id = col.decks.add_normal_deck_with_name("Lots of Kanji").id with open("jouyou-kanji.csv", "r") as csv_file: # make sure to use space as the delimiter (interesting choice but very readable in the raw form) # example line: '譜 "musical score" fu' csv_lines = csv.reader(csv_file, delimiter=" ") for line in csv_lines: note = Note(col, note_type_id) # make up a unique ID by assuming the Kanjis are unique note.guid = f'kanji-{line[0]}' # first column is Kanji note["Back"] = line[0] # second is english translation note["Front"] = line[1] # calculate Hiragana automatically from Kanji note["Hiragana"] = kanji_conv.to_hiragana(line[0]) col.add_note(note, deck_id)
Now, let's do something with the Hiragana we calculated. Let's start by adding a second template that allows us to practice reading Hiragana.
To organize our templates a bit better, we first take front.html and
back.html and move it into a new directory templates/kanji together with
the script animation.js. Then we create
a new front and back HTML in templates/hiragana. When done, the directory
structure should look like this:
templates
kanji
animation.jsfront.htmlback.htmlhiragana
front.htmlback.htmlFor templates/hiragana/front.html, let's show the Hiragana and ask to
translate into English:
Translate to English please:<br> {{Hiragana}}
On the back side in templates/hiragana/back.html, let's show English (Front):
{{FrontSide}} <hr id="answer"> <dl> <dt>English</dt> <dd id="kanji">{{Front}}</dd> </dl>
Let's use parcel to prepare our templates for Anki. By using **/*.html,
we can translate all templates in one go in our shell:
node_modules/.bin/parcel build templates/**/*.html
Next we will update our note type to include both templates, and to provide a
deck override option. The deck override option (did in the dictionary) is a
quick way to put newly created cards from a specific template in a different
deck than the one you specify when creating the note. Let's specify this only
for Hiragana and keep the default value of None for the Kanji one:
with open("dist/kanji/front.html", "r") as front_file: with open("dist/kanji/back.html", "r") as back_file: kanji_front_html = front_file.read() kanji_back_html = back_file.read() with open("dist/hiragana/front.html", "r") as front_file: with open("dist/hiragana/back.html", "r") as back_file: hiragana_front_html = front_file.read() hiragana_back_html = back_file.read() hiragana_deck_id = col.decks.add_normal_deck_with_name("Lots of Hiragana").id note_type = { 'id': 0, # the 0 has no effect, the actual ID will be the timestamp at the time of adding the note type 'name': "My cool note type", 'type': 0, 'mod': 0, 'usn': 0, 'sortf': 0, 'did': None, 'tmpls': [ { 'name': 'English to Japanese', 'ord': 0, 'qfmt': kanji_front_html, 'afmt': kanji_back_html, 'bqfmt': '', 'bafmt': '', 'did': None, 'bfont': '', 'bsize': 0, }, { 'name': 'Hiragana to English', 'ord': 1, 'qfmt': hiragana_front_html, 'afmt': hiragana_back_html, 'bqfmt': '', 'bafmt': '', # Hiragana should ignore the deck below and always be stored in # a separate deck 'did': hiragana_deck_id, 'bfont': '', 'bsize': 0, } ], 'flds': [ # Example { 'name': "Front", 'ord': 0, # Field No.1, this one must always be non-empty # not sure what this stuff does, just use CSS for styling 'sticky': False, 'rtl': False, 'font': 'Arial', 'size': 20, 'description': '', 'plainText': False, 'collapsed': False, 'excludeFromSearch': False, 'id': 0, 'tag': None, 'preventDeletion': False }, { 'name': "Back", 'ord': 1, # Field No.2, can be empty 'sticky': False, 'rtl': False, 'font': 'Arial', 'size': 20, 'description': '', 'plainText': False, 'collapsed': False, 'excludeFromSearch': False, 'id': 1, 'tag': None, 'preventDeletion': False }, { 'name': "Hiragana", 'ord': 2, 'sticky': False, 'rtl': False, 'font': 'Arial', 'size': 20, 'description': '', 'plainText': False, 'collapsed': False, 'excludeFromSearch': False, 'id': 1, 'tag': None, 'preventDeletion': False } ], 'css': '', # instead of putting it into the HTML you could also set CSS here # note sure what the rest does 'latexPre':'\\documentclass[12pt]{article}\n\\special{papersize=3in,5in}\n\\usepackage[utf8]{inputenc}\n\\usepackage{amssymb,amsmath}\n\\pagestyle{empty}\n\\setlength{\\parindent}{0in}\n\\begin{document}\n', 'latexPost':'\\end{document}', 'latexSvg': False, 'req': [ [ 0, 'any', [ 0 ] ] ], 'originalStockKind': 1 }
Nice, the next time we run the script, we will get two cards for each note: one for Kanji and one for Hiragana. By using the deck override option we put the Hiragana cards in a separate deck (instead of adding them to the very end of the deck we already have, which would be the default).
Let's run the script again so we can see if it worked:
pipenv install # unless you have installed dependencies already pipenv run python create_from_scratch_with_csv.py
When importing back into Anki, you have to allow the import operation to change the note type:
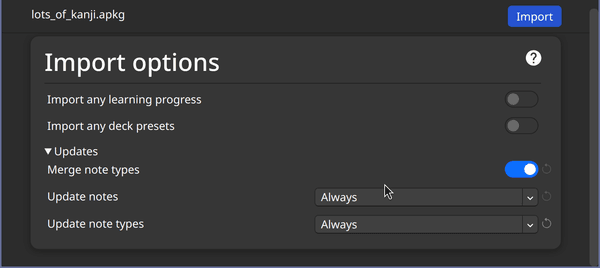 Making sure the imported APKG will update the note type with Hiragana by selecting "Always"
Making sure the imported APKG will update the note type with Hiragana by selecting "Always"
After the import, you'll see a new deck appear in your Anki:
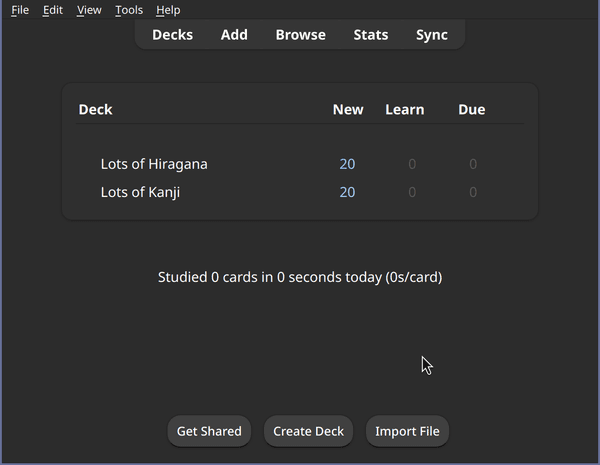 Hiragana and Kanji in separate decks using the did option on template
Hiragana and Kanji in separate decks using the did option on template
And the Hiragana deck contains our brand new Hiragana cards for practicing:
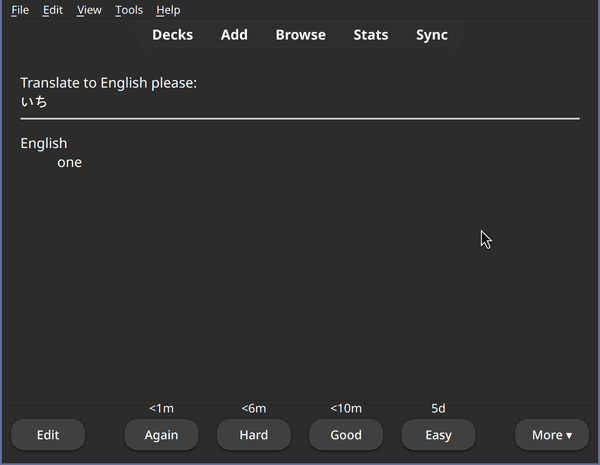 Our Hiragana cards in Anki
Our Hiragana cards in Anki
Quite the ride! Without investing a lot of time ourselves, we managed to make about 2000 notes, resulting in about 4000 cards.
This was possible only because we were able to rely on the work of others and to successfully synthesize this work. In our case, we used a list of vocabulary from Github, and combined it with dictionary data using python. By using a similar approach and synthesizing data, or otherwise coming up with it in code (say, generating random math exercises), you can build cards for almost anything imaginable. It's in situations like these where you are dealing with incomplete data, or otherwise want to avoid having to do something a thousand times over, where using python code with Anki is at its most useful.
At this point, you already know most of the ingredients to the Kartenaale cards secret sauce. Some important aspects are using npm packages, generating APKGs and note types from python code, using scripts to pre-process, complement and generate note data. With this, you can already achieve a lot.
If you had trouble following along, please check out the solution on University of Vienna Gitlab.
There still is one thing about are cards that we should fix, though: when you test the cards on your phone in airplane mode, you'll notice that the animated Kanji fail to pop up. It turns out we were actually cheating: we only added offline support for the code of HanziWriter itself, but relied on the default behavior of that code to load character data from a CDN (content delivery network), that is, from the internet. Consequently, our cards don't really have offline support yet. Turns out, this can be solved in Anki, and there is more than one way to do it, but finding an approach that worked good on all Anki platforms took me a long time. In the next post, I'd like to share with you, how I made HanziWriter work offline on Kartenaale cards.
As always, I hope you found this post enjoyable and will be back with me next time, when we do even more Anki hacking!
Then you're in luck, this post is part of the series Anki scripting crimes: Doing what you have to do for advanced scripting on Anki cards and you can continue reading straight away with Anki scripting crimes, part 4: Using media storage to implement offline support.
If you like the post or have thoughts on it, don't hesitate to write an E-Mail and tell me about it. You can reach me under philipp.pospischil@tapirbug.at.
Interested in more weird tech content? Check out all posts or check the home page.
Want to stay up-to-date? You can subscribe to this blog by adding the URL https://tapirbug.xyz to your favorite feed reader. Atom, RSS and JSON subscriptions are supported.